Google anunció un notable marco de clasificación llamado Term Weighting BERT (TW-BERT) que mejora los resultados de búsqueda y es fácil de implementar en los sistemas de clasificación existentes.
Aunque Google no ha confirmado que esté utilizando TW-BERT, este nuevo marco es un gran avance que mejora los procesos de clasificación en todos los ámbitos, incluida la expansión de consultas. También es fácil de implementar, lo que, en mi opinión, hace que sea más probable que esté en uso.
TW-BERT tiene muchos coautores, entre ellos Marc Najork , científico investigador distinguido de Google DeepMind y ex director sénior de ingeniería de investigación de Google Research.
Es coautor de muchos trabajos de investigación sobre temas relacionados con los procesos de clasificación y muchos otros campos.
Entre los artículos, Marc Najork figura como coautor:
- Sobre la optimización de las métricas Top-K para modelos de clasificación neuronal – 2022
- Modelos de lenguaje dinámico para contenido en continua evolución – 2021
- Repensar la búsqueda: convertir a los diletantes en expertos en dominios – 2021
- Transformación de funciones para modelos de clasificación neuronal – – 2020
- Aprender a clasificar con BERT en TF-Ranking – 2020
- Coincidencia de texto semántico para documentos de formato largo – 2019
- TF-Ranking: biblioteca escalable de TensorFlow para aprender a clasificar, 2018
- El marco LambdaLoss para la optimización de métricas de clasificación – 2018
- Aprendiendo a clasificar con sesgo de selección en la búsqueda personal – 2016
¿Qué es TW-BERT?
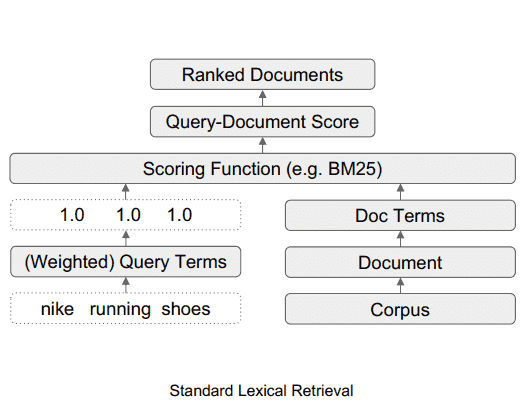
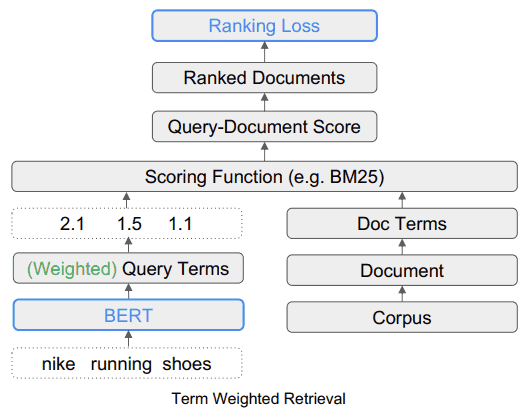
TW-BERT es un marco de clasificación que asigna puntajes (llamados pesos) a las palabras dentro de una consulta de búsqueda para determinar con mayor precisión qué documentos son relevantes para esa consulta de búsqueda.
TW-BERT también es útil en Query Expansion.
Query Expansion es un proceso que reafirma una consulta de búsqueda o le agrega más palabras (como agregar la palabra «receta» a la consulta «sopa de pollo») para hacer coincidir mejor la consulta de búsqueda con los documentos.
Agregar puntajes a la consulta ayuda a determinar mejor de qué se trata la consulta.
TW-BERT une dos paradigmas de recuperación de información
El artículo de investigación analiza dos métodos diferentes de búsqueda. Uno basado en estadísticas y el otro en modelos de aprendizaje profundo.
Sigue una discusión sobre los beneficios y las deficiencias de estos diferentes métodos y sugiere que TW-BERT es una forma de unir los dos enfoques sin ninguna de las deficiencias.
Escriben:
“Estos métodos de recuperación basados en estadísticas brindan una búsqueda eficiente que se amplía con el tamaño del corpus y se generaliza a nuevos dominios.
Sin embargo, los términos se ponderan de forma independiente y no tienen en cuenta el contexto de toda la consulta».
Luego, los investigadores notan que los modelos de aprendizaje profundo pueden descubrir el contexto de las consultas de búsqueda.
Se explica:
«Para este problema, los modelos de aprendizaje profundo pueden realizar esta contextualización sobre la consulta para proporcionar mejores representaciones de términos individuales».
Lo que proponen los investigadores es el uso de TW-Bert para unir los dos métodos.
El avance se describe:
“Unimos estos dos paradigmas para determinar cuáles son los términos de búsqueda más relevantes o no relevantes en la consulta…
Luego, estos términos se pueden ponderar hacia arriba o hacia abajo para permitir que nuestro sistema de recuperación produzca resultados más relevantes”.
Ejemplo de ponderación de términos de búsqueda TW-BERT
El trabajo de investigación ofrece el ejemplo de la consulta de búsqueda, «zapatillas Nike para correr».
En términos simples, las palabras “Zapatillas para correr Nike” son tres palabras que un algoritmo de clasificación debe entender de la forma en que el buscador pretende que se entienda.
Explican que enfatizar la parte «en ejecución» de la consulta mostrará resultados de búsqueda irrelevantes que contienen marcas distintas a Nike.
En ese ejemplo, la marca Nike es importante y por eso el proceso de clasificación debe requerir que las páginas web candidatas contengan la palabra Nike en ellas.
Las páginas web candidatas son páginas que se tienen en cuenta para los resultados de búsqueda.
Lo que hace TW-BERT es proporcionar una puntuación (llamada ponderación) para cada parte de la consulta de búsqueda para que tenga el mismo sentido que la persona que ingresó la consulta de búsqueda.
En este ejemplo, la palabra Nike se considera importante, por lo que se le debe dar una puntuación más alta (ponderación).
Los investigadores escriben:
“Por lo tanto, el desafío es que debemos asegurarnos de que Nike” tenga un peso lo suficientemente alto y al mismo tiempo proporcione zapatillas para correr en los resultados finales devueltos”.
El otro desafío es comprender el contexto de las palabras «correr» y «zapatos» y eso significa que la ponderación debe inclinarse más para unir las dos palabras como una frase, «zapatos para correr», en lugar de ponderar las dos palabras de forma independiente.
Este problema y la solución se explica:
“El segundo aspecto es cómo aprovechar términos de n-gramas más significativos durante la puntuación.
En nuestra consulta, los términos «correr» y «zapatillas» se manejan de forma independiente, lo que puede coincidir igualmente con «calcetines para correr» o «zapatillas para patinar».
En este caso, queremos que nuestro perro perdiguero funcione en un nivel de términos de n-gramas para indicar que las «zapatillas para correr» deben tener un peso superior al puntuar».
Resolución de limitaciones en los marcos actuales
El documento de investigación resume la ponderación tradicional como limitada en las variaciones de las consultas y menciona que esos métodos de ponderación basados en estadísticas funcionan menos bien para escenarios de tiro cero.
Zero-shot Learning es una referencia a la capacidad de un modelo para resolver un problema para el que no ha sido entrenado.
También hay un resumen de las limitaciones inherentes a los métodos actuales de expansión de términos.
La expansión de términos es cuando se usan sinónimos para encontrar más respuestas a consultas de búsqueda o cuando se infiere otra palabra.
Por ejemplo, cuando alguien busca «sopa de pollo», se infiere que significa » receta de sopa de pollo».
Escriben sobre las deficiencias de los métodos actuales:
“…estas funciones de puntuación auxiliares no tienen en cuenta los pasos de ponderación adicionales llevados a cabo por las funciones de puntuación utilizadas en los recuperadores existentes, como las estadísticas de consultas, las estadísticas de documentos y los valores de hiperparámetros.
Esto puede alterar la distribución original de los pesos de los términos asignados durante la puntuación final y la recuperación”.
A continuación, los investigadores afirman que el aprendizaje profundo tiene su propio bagaje en forma de complejidad a la hora de implementarlos y un comportamiento impredecible cuando se encuentran con nuevas áreas para las que no estaban capacitados previamente.
Entonces, aquí es donde TW-BERT entra en escena.
TW-BERT une dos enfoques
La solución propuesta es como un enfoque híbrido.
En la siguiente cita, el término IR significa Recuperación de información.
Escriben:
“Para cerrar la brecha, aprovechamos la solidez de los recuperadores léxicos existentes con las representaciones de texto contextual proporcionadas por modelos profundos.
Los recuperadores léxicos ya brindan la capacidad de asignar pesos para consultar términos de n-gramas al realizar la recuperación.
Aprovechamos un modelo de lenguaje en esta etapa de la canalización para proporcionar ponderaciones adecuadas a los términos de n-grama de consulta.
Este BERT de ponderación de términos (TW-BERT) se optimiza de principio a fin utilizando las mismas funciones de puntuación que se utilizan en la canalización de recuperación para garantizar la coherencia entre el entrenamiento y la recuperación.
Esto lleva a mejoras en la recuperación cuando se usan las ponderaciones de términos producidos por TW-BERT mientras se mantiene la infraestructura IR similar a su contraparte de producción existente”.
El algoritmo TW-BERT asigna ponderaciones a las consultas para proporcionar una puntuación de relevancia más precisa con la que pueda trabajar el resto del proceso de clasificación.
Recuperación léxica estándar
Recuperación ponderada de términos (TW-BERT)
TW-BERT es fácil de implementar
Una de las ventajas de TW-BERT es que se puede insertar directamente en el proceso de clasificación de recuperación de información actual, como un componente directo.
“Esto nos permite implementar directamente nuestros pesos de término dentro de un sistema IR durante la recuperación.
Esto difiere de los métodos de ponderación anteriores que necesitan ajustar aún más los parámetros de un perro perdiguero para obtener un rendimiento de recuperación óptimo, ya que optimizan los pesos de términos obtenidos por heurística en lugar de optimizar de principio a fin”.
Lo importante de esta facilidad de implementación es que no requiere software especializado ni actualizaciones de hardware para agregar TW-BERT a un proceso de algoritmo de clasificación.
¿Google está utilizando TW-BERT en su algoritmo de clasificación?
Como se mencionó anteriormente, implementar TW-BERT es relativamente fácil.
En mi opinión, es razonable suponer que la facilidad de implementación aumenta las probabilidades de que este marco pueda agregarse al algoritmo de Google.
Eso significa que Google podría agregar TW-BERT en la parte de clasificación del algoritmo sin tener que hacer una actualización del algoritmo central a gran escala.
Además de la facilidad de implementación, otra cualidad que se debe buscar al adivinar si un algoritmo podría estar en uso es qué tan exitoso es el algoritmo para mejorar el estado actual del arte.
Hay muchos trabajos de investigación que solo tienen un éxito limitado o ninguna mejora. Esos algoritmos son interesantes, pero es razonable suponer que no llegarán al algoritmo de Google.
Los que son de interés son los que tienen mucho éxito y ese es el caso de TW-BERT.
TW-BERT tiene mucho éxito. Dijeron que es fácil colocarlo en un algoritmo de clasificación existente y que funciona tan bien como los «clasificadores neuronales densos».
Los investigadores explicaron cómo mejora los sistemas de clasificación actuales:
“Usando estos marcos de recuperación, mostramos que nuestro método de ponderación de términos supera las estrategias de ponderación de términos de referencia para tareas en el dominio.
En tareas fuera del dominio, TW-BERT mejora las estrategias de ponderación de referencia, así como los clasificadores neuronales densos.
Además, mostramos la utilidad de nuestro modelo al integrarlo con los modelos de expansión de consultas existentes, lo que mejora el rendimiento sobre la búsqueda estándar y la recuperación densa en los casos de disparo cero.
Esto motiva que nuestro trabajo pueda proporcionar mejoras a los sistemas de recuperación existentes con una mínima fricción de incorporación”.
Esas son dos buenas razones por las que TW-BERT ya podría ser parte del algoritmo de clasificación de Google.
- Es una mejora general de los marcos de clasificación actuales.
- Es fácil de implementar
Si Google implementó TW-BERT, eso puede explicar las fluctuaciones de posiciones que las herramientas de monitoreo de SEO y los miembros de la comunidad de marketing de búsqueda han estado informando durante el último mes.
En general, Google solo anuncia algunos cambios en la clasificación, particularmente cuando causan un efecto notable, como cuando Google anunció el algoritmo BERT.
En ausencia de confirmación oficial, solo podemos especular sobre la probabilidad de que TW-BERT sea parte del algoritmo de clasificación de búsqueda de Google.
Sin embargo, TW-BERT es un marco notable que parece mejorar la precisión de los sistemas de recuperación de información y podría ser utilizado por Google.
Lea el artículo de investigación original:
Ponderación de términos de consulta de extremo a extremo (PDF)
Página web de investigación de Google:
Ponderación de término de consulta de extremo a extremo
Imagen destacada de Shutterstock/TPYXA Ilustración




