La actualización HCU de Google castigó el contenido de IA de baja calidad después de todo. En este caso de estudio, muestro por qué y cómo detectarlo.
Después del comienzo anticlimático de la Actualización de contenido útil de Google, el impacto se hizo visible hacia el final del lanzamiento de 2 semanas. Las expectativas iniciales de que el contenido de IA se vería afectado no se cumplieron, hasta ahora . Encontré muchos ejemplos de dominios que fueron degradados debido al contenido de IA.
Dado que la actualización principal de septiembre se implementó justo cuando finalizó la HCU, proporcionaré un análisis detallado de los dominios la próxima semana. En esta publicación, presento un ejemplo de un dominio que fue golpeado por HCU y castigado por usar contenido de IA de baja calidad .
Qué tan fácil es detectar contenido pobre de IA
Un buen ejemplo de contenido de IA mal creado es throughtheclutter.com, un dominio que proporciona perfiles de celebridades e historias de películas. Es el nivel de calidad del contenido lo que castiga la actualización de HCU.
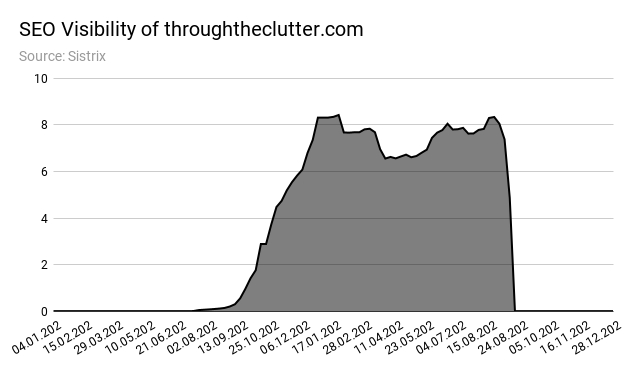
En su apogeo, throughtheclutter.com alcanzó alrededor de 1 millón de usuarios mensuales. El 30 de agosto, las filas comenzaron a caer bruscamente. Una semana después, el tráfico se redujo a casi 0.
Incluso antes de mirar el tráfico, puede saber que algo está pasando con el dominio mirando el formato de texto #walloftext.
La visibilidad SEO del dominio (captura de pantalla a continuación) muestra el desarrollo de tráfico típico para sitios que escalan agresivamente con contenido de IA: un aumento repentino, una meseta y una fuerte disminución.
Para probar que el texto fue creado por IA, analicé una muestra con dos herramientas detectoras de contenido de IA diferentes.
La muestra de contenido es un texto sobre Tom Hanks (ver captura de pantalla arriba): https://www.throughtheclutter.com/thomas-jeffrey-hanks-3063.php
Comparé los resultados con una sección de la página de Wikipedia de Tom Hank: https://en.wikipedia.org/wiki/Tom_Hanks#1980s:_Early_work
Medición de la huella visual con GLTR
La primera herramienta es GLTR , una herramienta de IBM Watson y Harvard NLP basada en GPT-2. Mide la huella visual del texto para estimar la probabilidad de que se genere automáticamente (piense: contenido ai).
Puede ver que el texto de througtheclutter.com tiene muchas menos palabras rojas y moradas que el texto de Wikipedia (captura de pantalla a continuación).
Salida GLTR para throughtheclutter.com
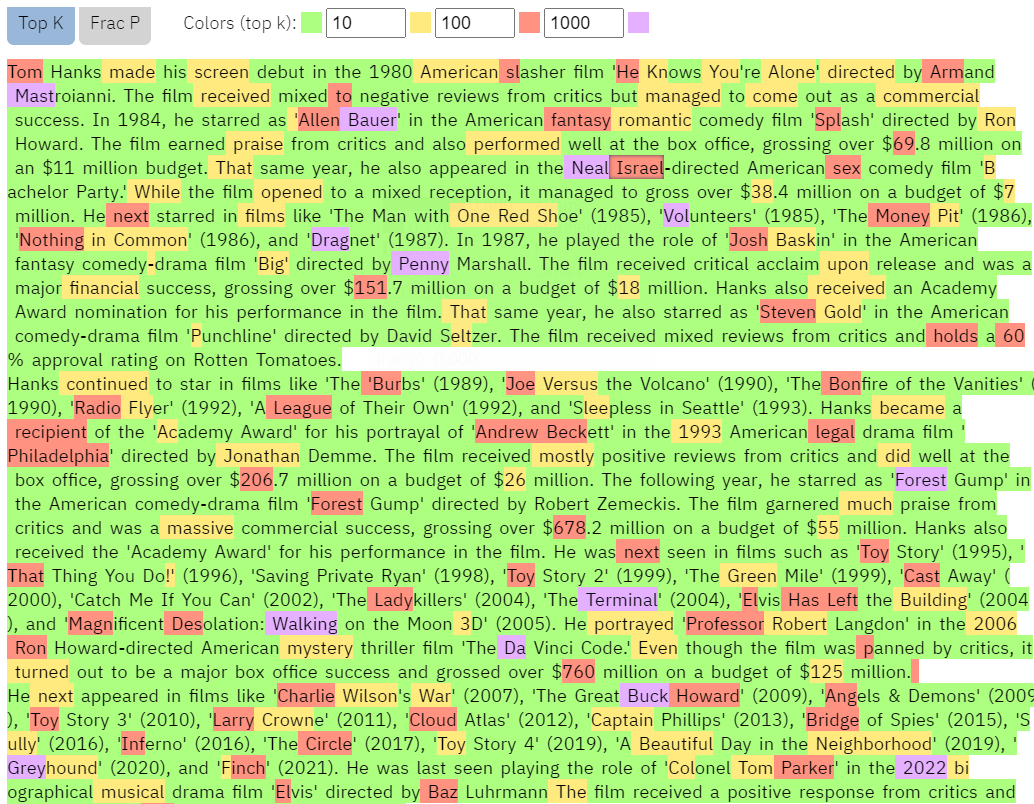
Análisis GLRT de la página de Tom Hanks de throughtheclutter.com
Las palabras rojas y moradas son «sorprendentes» en el modelo GPT-2 de GLTR, lo que significa que es menos probable que una IA las prediga. Como resultado, cuantas más palabras verdes tenga un texto, más probable es que sea escrito por una IA.
Salida GLTR para wikipedia.org
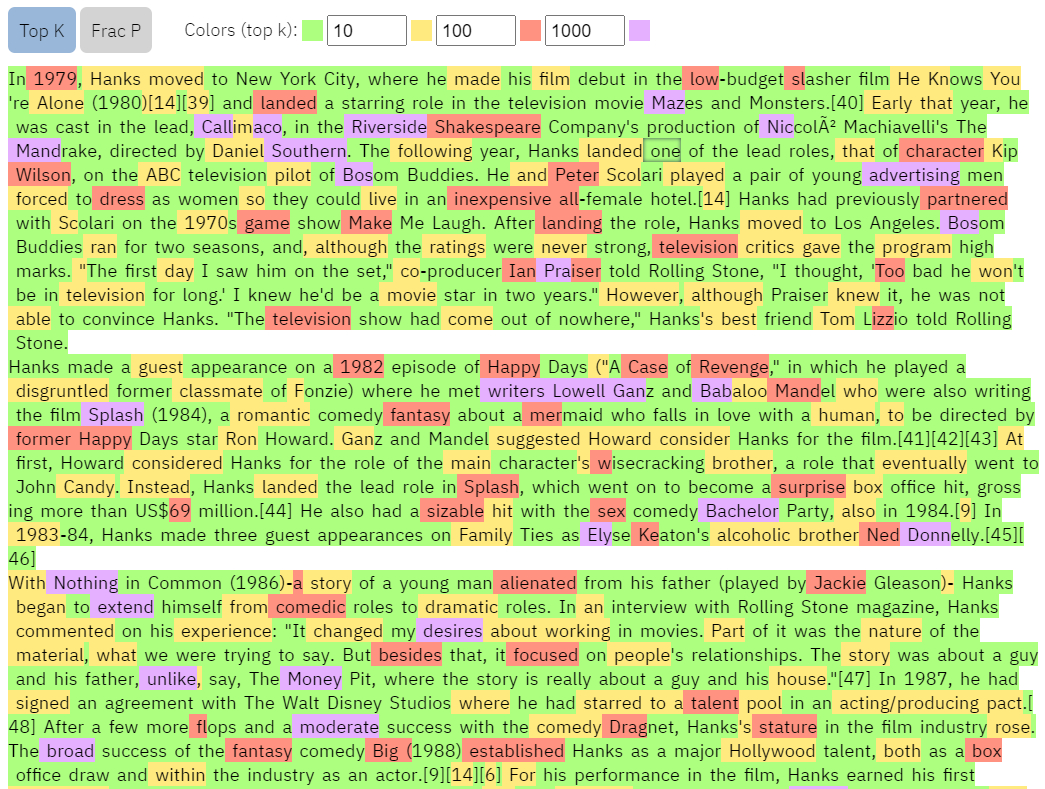
Análisis GLRT de la página de Tom Hanks de wikipedia.org
Cuando llevamos esto un paso más allá y comparamos los histogramas de las 10 principales predicciones de palabras, podemos ver una confianza relativamente alta en todas las modalidades.
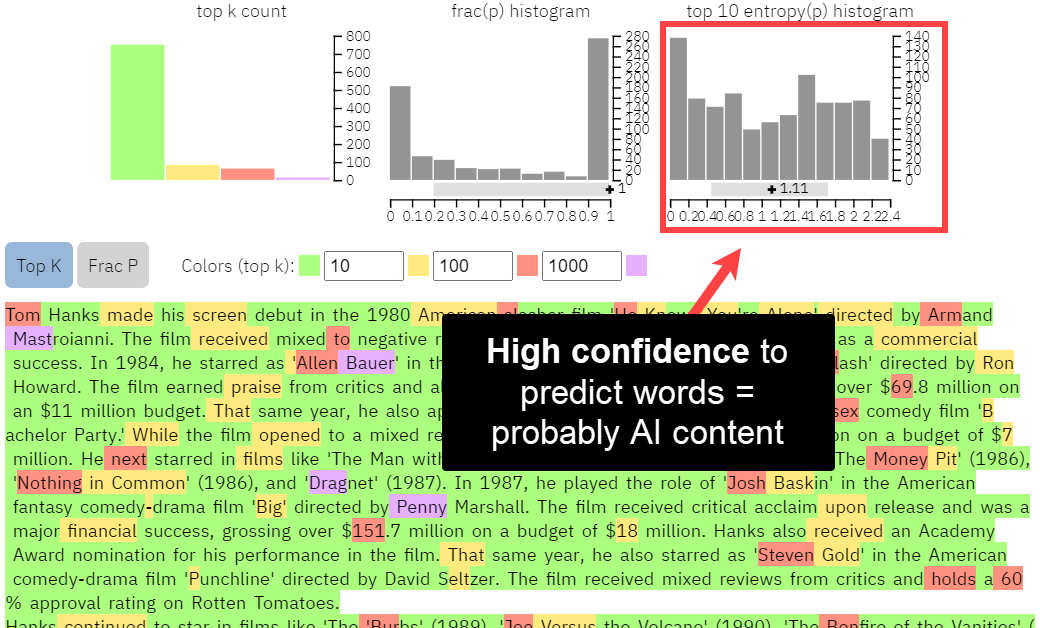
Histograma GLTR para el contenido de throughtheclutter.com
El contenido de Wikipedia, por otro lado, tiene poca confianza en los límites inferiores y mayor confianza en los límites superiores, lo que significa que el texto es más difícil de predecir para el modelo GPT-2. Es más probable que el contenido sea creado por humanos.
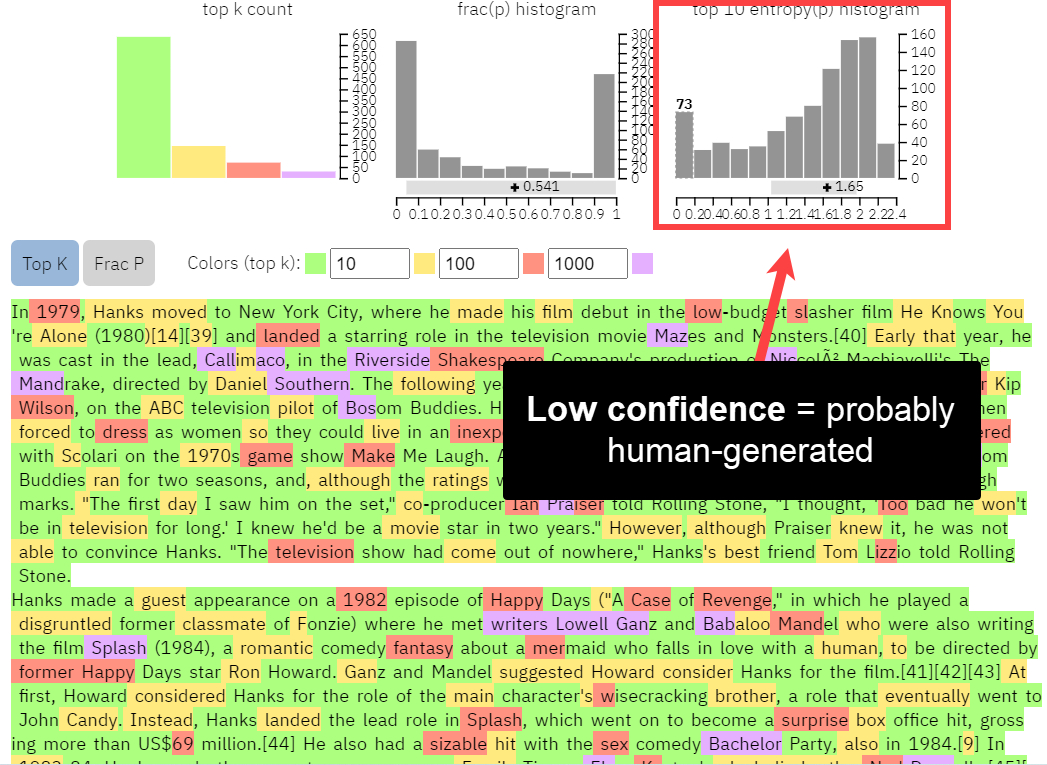
Histograma GLTR para el contenido de wikipedia.org
La tecnología en GPT, que significa Transformador preentrenado generativo, puede predecir el texto en función de las palabras anteriores. Google puede detectar contenido de IA simplemente en función de cuán «predecible» es el texto, especialmente en comparación con todo el otro contenido sobre el mismo tema en su corpus.
Detector de salida Huggingface
La segunda herramienta de detección de contenido de IA, el detector de salida GPT-2 de Huggingface, también se basa en la biblioteca de GPT-2, pero usa parámetros 1.5b en lugar de los 117M de GLTR. La demostración solo analiza los primeros 510 tokens, que son datos suficientes para este caso de estudio.
El detector de salida encuentra un 19% de probabilidad de que el texto de throughtheclutter.com sea falso .

El detector de salida de Huggingface encuentra un 19 % de probabilidad de contenido de IA
Eso parece bajo al principio, pero en realidad es bastante alto en comparación con el 0,02% probablemente para el texto de Wikipedia.
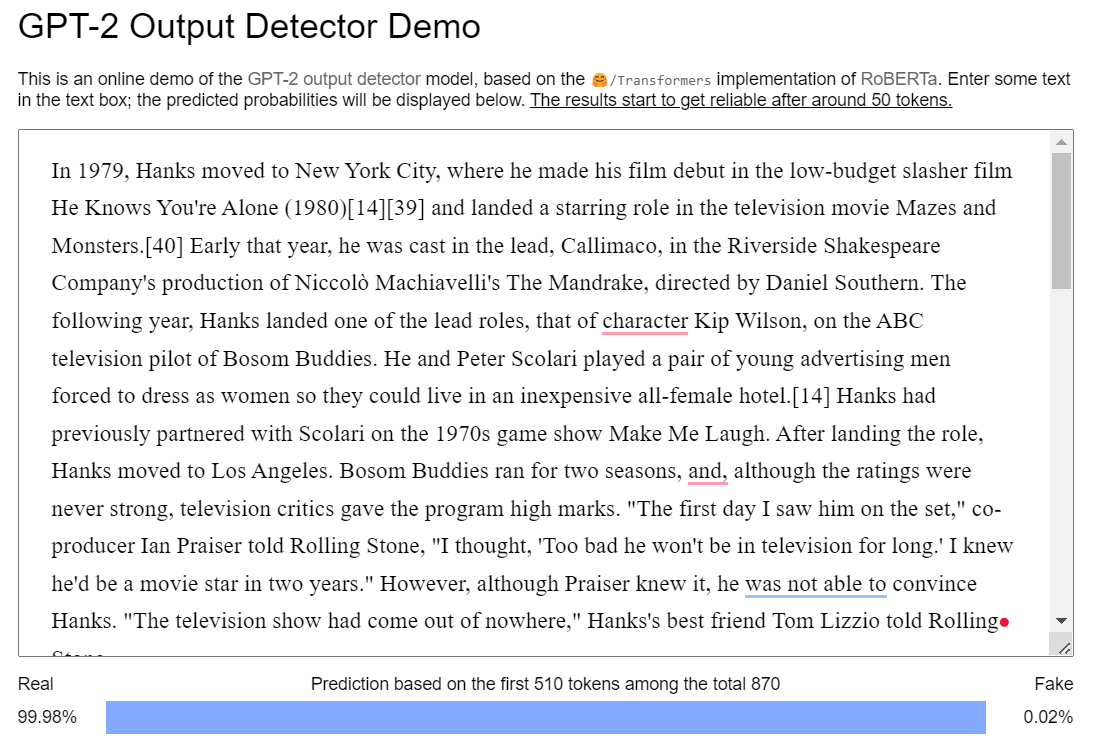
La página de Tom Hanks de Wikipedia tiene una probabilidad del 0,02 % de contenido de IA
Conclusión
Muchas empresas que usaban IA para crear contenido pero aseguraban alta calidad a través de revisiones editoriales y pulido humano temían que la actualización de HCU las castigara. Ese resultó no ser el caso. En cambio, Google va a por el fondo del barril y elimina los contenidos de muy baja calidad de las SERPs..
El movimiento estratégico para las empresas no es aceptar el contenido de IA por completo, sino usar herramientas como la biblioteca pública OpenAI GPT-2 en sus flujos de trabajo de creación de contenido para disminuir la previsibilidad del texto y aumentar la probabilidad de generar tráfico orgánico.
Aún más importante, los integradores deben centrarse en el valor del usuario y la obtención de información en sus estrategias de contenido, sin importar quién o qué cree el contenido. El muro de texto en throughtheclutter.com (nombre de dominio irónico) no es malo porque es contenido de IA, sino porque el formato y la presentación de los datos no brindan valor al usuario. Es difícil de entender cognitivamente y no contribuye a la lista de películas de Tom Hanks, la intención del usuario objetivo de la página.





