El titulo sólo me recordó el meme de la pagina SEO Memes.
Es de SEOs
Posted by SEO Memes on Friday, November 29, 2019
Ya en serio…
Siempre he sostenido que un problema que se tiene al hacer SEO sin tener mucho fundamento técnico es que cuando se requiere tomar decisiones técnicas se puede hacer de la forma equivocada, con dudas o con temor.
Conocer las partes técnicas de un sitio web es fundamental, no es necesario ser un experto desarrollador, no, con conocer un poco de HTML y algunos conceptos basta, pero casi nadie los enseña o se enseñan tan deprisa que da la sensación de que es algo sin importancia.
Es así que llegue al tema de los Meta tags, específicamente el Meta tag Robots. Muchos dan por hecho que estos pequeños detalles no evolucionan, o se mantienen estáticos, y muchas veces hay cambios que vale la pena revisar, como es el caso de este posts.
A veces lograr guiar a los motores de búsqueda para rastrear e indexar tu web como lo deseas o piensas puede ser complicado sin el conocimiento adecuado, y para esto es que existe el meta tag en mención.
Mientras que desde robots.txt le dices al bot que accesar y que no, en éste no puedes decirle que indexar y que no, y aunque antes se podia, en Julio de 2019 fue oficialmente puesto como obsoleto (ver anuncio en Webmaster central blog).
¿Qué es el robots meta tag o metaetiqueta de robots?
Es un fragmento de código HTML que le dice a los motores de búsqueda como rastrear o indexar una página (ojo, pagina = una URL, no una web completa).
Este código HTML se coloca en la sección <head> y se ve algo así:
<meta name=»robots» content=»noindex» />
¿Cómo puedo saber si tengo presente esta metaetiqueta y con qué valores?
Hay dos formas sencillas de hacerlo, la más simple es ver el código fuente de la página (Ctrl + U, clic derecho-> ver código fuente) y una vez ahí, puedes buscar la palabra “robots” (CTRL + F o CTRL + B) para ubicarlo, o ir a la sección <head>.
Ahora bien, si eres de los que ver código fuente hace que te de nauseas, o cuando lo ves comprimido comienzas a pensar “qué diablos estoy haciendo”, entonces también puedes usar esta extensión que te sugiero: SEO Minion.
Lo que me gusta de esta extensión es que puedes instalarla tanto en Chrome como en Firefox.
Una vez instalada la extensión, busca su icono haz clic sobre él y te abrirá un recuadro como éste:
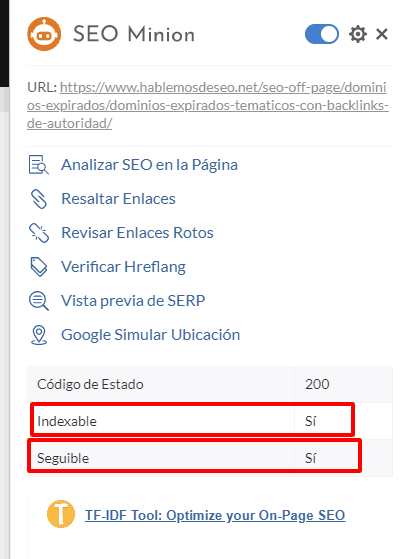
Donde nos interesa para este caso lo que he puesto en recuadro rojo. Aquí puedes ver si está presente o no la metaetiqueta Robots y que valores tiene (más adelante explicó que significa cada valor).
Básicamente en este ejemplo me está diciendo que el meta robots permite que la página se indexe (INDEX) y que todos sus enlaces se sigan (FOLLOW). Si aun así no estas convencido, puedes hacer clic en la opción “Analizar SEO en la página” y veras algo como esto:
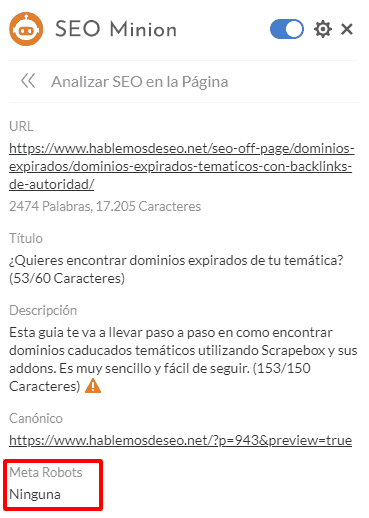
Si observas, dice que el meta robots no está presente y te puedes estar preguntando como es que al inicio decía que era INDEX y FOLLOW y aquí dice que no tiene presente la metaetiqueta.

La verdad es muy sencillo, ésta metaetiqueta tiene un valor por default: INDEX,FOLLOW, es decir, que si la etiqueta no está presente, por defecto su valor será éste, así que no te preocupes si no la encuentras, a menos que su valor tuviese que ser otro.
¿Por qué nos debe importar la meta Robots en el SEO?
El uso más común para el meta robots es para evitar que una página aparezca en los resultados de búsqueda (indexe), pero tiene otros usos.
¿Qué contenido podrías no querer que aparezca en los resultados de búsqueda?
- Paginas en desarrollo o prueba
- Administradores (paneles, etc)
- Páginas de “gracias por” (tu compra, suscribirte, etc)
- Páginas con thin content
- Páginas que no le aporten valor al usuario
- Landing Pages de campañas de publicidad
- Páginas de promociones, lanzamientos, etc
Sé que hay más usos, pero estos se me vinieron a la mente mientras escribía.
A medida tu sitio va creciendo más tienes que lidiar con el tema de rastreo e indexación, y cuando tu sitio es grande debes procurar que Google y otros rastreen e indexen tu web de forma eficiente. Una combinación entre meta Robots – robots.txt y sitemap ese importante en estas circunstancias para el SEO.
¿Cómo se configura el meta robots?

Meta robots se compone de 2 atributos: Nombre (name) y contenido (content) y se debe especificar un valor para cada uno de ellos.
El valor default de meta robots es:
<meta name=»robots» content=»all» />
Esto significa que todos los robots pueden indexar y seguir todos los enlaces de la página o lo que es igual a poner content=”index,follow”. Si el robots meta tag no está presente, entonces se toma el valor antes mencionado.
El atributo name
Este atributo le dice a los crawler que lo lee si debería seguir las instrucciones especificadas en él. A este valor también se le conoce como user-agent (UA) porque los rastreadores (crawlers) necesitan identificarse con su propio UA para solicitar una página.
Básicamente el UA representa el navegador que está visitando la pagina, y en le caso de los bots, el crawler que lo esta haciendo, por ejemplo los UA de Google son: Googlebot y Googlebot-image.
Si colocas el valor “robots”, estas diciendo que aplica para todos los carwlers y puedes agregar tantos robots meta tags como necesites, por ejemplo si a cada UA quieres darle un valor diferente, quizá quieras que las imágenes de tu sitio se muestren en Bing pero no en Google, en este caso, en el <head> de tu página pondrías los siguientes meta tags:
<meta name=»googlebot-image» content=»noindex» />
<meta name=»MSNBot-Media» content=»INDEX» />
El atributo content
Este atributo tiene la información de cómo debe ser rastreado e indexada la página.
Esta es la lista de valores soportados por el atributo content por Google:
All
Es el valor default como vimos unas líneas atrás, y no es necesario colocar el meta tag si lo que quieres es que sea All.
No soportada por BING.
Noindex
Le indica al motor de búsqueda que no indexe la página. Eso significa que no debe mostrarse en los resultados de búsqueda.
<meta name=»robots» content=»noindex» />
Nofollow
Detiene a los robots indicados para que no rastreen los enlaces en la página. Ten en cuenta que estas URLs (enlaces) siempre pueden indexarse, principalmente si tienen backlinks apuntándoles.

<meta name=»robots» content=»nofollow» />
None
Es la combinacion de NOINDEX,NOFOLLOW, aunque es preferible no usarlo pues hay otros motores como Bing que no lo soportan, asi que mejor a la antigüita.
<meta name=»robots» content=»none» />
No soportada por BING.
Noarchive
Previene de que Google muestre una copia de cache de la página en los resultados de búsqueda.
<meta name=»robots» content=»noarchive» />
Notranslate
Previene que Google ofrezca traducir la página en los resultados de búsqueda.
<meta name=»robots» content=»notranslate» />
No soportada por BING.
noimageindex
Impide que Google indexe imágenes incrustadas en la página.
<meta name=»robots» content=»noimageindex» />
No soportada por BING.

unavailable_after
Le indica a Google que no muestre la pagina en los resultados de búsqueda después de una fecha y hora determinada.
En otras palabras, es una NOINDEX con un cronometro. La fecha debe ser especificada usando el formato RFC 850.
<meta name=»robots» content=»unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT» />
No soportada por BING.
Nosnippet
Se excluye de todos los fragmentos de texto y video dentro de los resultados de búsqueda. También funciona como noarchive al mismo tiempo.
<meta name=»robots» content=»nosnippet» />
Desde octubre de 2019, Google ofrece un mejor control de si quieres y como mostrar tus snippets en los resultados de búsqueda. Esto se debe en parte a la Directiva Europea de Copyright. Esta legislación afecta a todos los sitios web ¿Cómo? Pues Google ya no muestra snippets (texto, imágenes o video) de tu sitio a los usuarios (al momento de escribir esto, el único país que ha implementado esto es Francia) a menos que tu optes por usar su “nuevo” robots meta tag. Más abajo esta la descripción de todo lo nuevo y como funciona, pero si quieres una solución rápida solo debes poner el siguiente meta tag en tude todas las páginas que necesites para decirle a Google que no quieres restricciones en tus snippets.
<meta name=»robots» content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1″ />
Ojo, si usas WordPress y estas usando Yoast by SEO, este fragmento de código HTML se agrega en automático en cada página a menos que tú las pongas como NOINDEX o NOSNIPPET.
Max-snippet
Sirve para especificar el número de caracteres que Google puede mostrar en sus snippets. SI pones 0 evitará que aparezca el snippet, -1 indica que no hay límite en el texto a mostrar.
Con el siguiente ejemplo, limitamos a 160 caracteres el snippet:
<meta name=»robots» content=»max-snippet:160″ />
No soportada por BING.
Max-image-preview
Le indica a Google si y que tan grande puede usar una imagen para los snippets. Esta directiva tiene 3 posibles valores:
- None: no mostrara imágenes en los snippets
- Standard: se muestra la imagen previa predeterminada
- Large: se muestra la imagen más grande que se pueda
Ejemplo:
<meta name=»robots» content=»max-image-preview:large» />
No soportada por BING.
max-video-preview
Configura el numero de segundos máximo para un snippet de video. Como en el caso de la imagen, 0 deshabilita, -1 es para no poner límites.
Este ejemplo le dice a Google que muestre un máximo de 10 segundos:
<meta name=»robots» content=»max-video-preview:10″ />
No soportada por BING.

NOTA ESPECIAL: El atributo data-nosnippet
Junto a las nuevas directivas que se presentaron en Octubre del 2019 (ver mas arriba), Google tambien agrego algo muy interesante: el atributo HTML data-nosnippet.
Me imagino que te ha pasado (como a mi) que te esfuerzas escribiendo una meta descripción, y después de mucho tiempo de pulirla, Google decide poner cualquier otra cosa menos lo que hiciste. Por lo general es otro texto que se encuentra en la página en cuestión, por lo que data-nosnippet es la solución.
Puedes usar este tag para decirle a Google que partes del texto de la página NO QUIERES que se use como snippet. Lo puedes usar en DIV, SPAN, P, y SECTION y es un atributo booleano, es decir que solo debe colocarse sin ningún valor, mientras esté presente significa que lo estas activando, veamos un ejemplo.
<p>Este párrafo tiene info interesante que puede usarse en el snippet<span data-nosnippet> menos esta porque no quieres que se muestre.</span></p>
Otro ejemplo:
<div data-nosnippet>Este texto no va a aparecer en los snippets</div><div data-nosnippet=»true»>y tampoco este</div>
Usando el robots meta tag
La mayoría solo usan NOINDEX y/o NOFOLLOW, pero ahora ya sabes que este meta tiene mas opciones y algunas muy interesantes. Y ojo, todo lo mostrado en el post son directivas consideradas por Google, algunas no las consideran otros buscadores como Bing.
Se pueden usar muchas directivas a la vez y se pueden combinar pero si por error (o experimento) hay conflicto entre ellas, digamos pones NOINDEX,INDEX, Google va a tomar como instrucción la más restrictiva, en el ejemplo anterior seria NOINDEX.
Como se configura el robots meta tag en tu página
Ahora que ya conoces las diferentes opciones, ahora es tiempo de colocar el meta tag.
El meta tag pertenece a la sección HEAD, asi que dependiendo de cómo y con que este hecha tu web, deberás ir a dicha sección (página por página que necesites cambiar) y agregar el meta robots.
Pero bueno, sé que la mayoría usa WORDPRESS así usando Yoast o Rank Math lo puedes hacer muy fácil.

Evita errores de indexación y rastreo
Por lo general quieres que todo el contenido de valor de tu web se muestre en los resultados de busqueda y evitas que el contenido duplicado, thin content, etc queden fuera de la indexación, y mas aun si administras una web realmente grande, querras prestar atención a estos detalles para administrar bien el crawl Budget.
A continuación un par de los errores más comunes que se cometen (y he cometido)
Error 1: Mal manejo del sitemap
Cuando intentamos desindexar contenido usando el meta robots por lo general lo primero que pensamos es en sacarlo del SITEMAP, pero no lo hagas, espera hasta que este desindexado, sino, Google podría tardarse más en rastrear/leer la página y entender que no debe indexarla.
Si la página está presente en el sitemap, cuando Google la vea, la leerá y ahí encontrara el NOINDEX y el proceso será más rápido.
Error 2: no remover la directiva NOINDEX de un ambiente de producción
Evitar que una web en desarrollo se rastree e indexe es una buena práctica, pero algunas veces se pasa a producción y se nos olvida quitar esta opción y luego nos preguntamos porque G no indexa o nos da error en GSC.
El escenario anterior digamos que no es tan grave pues aplica por lo general a un sitio nuevo, pero que pasa cuando estamos haciendo un 301 y al nuevo dominio se nos olvida quitar el NOINDEX?
Lo primero que vas a ver es que el tráfico sigue llegando pues está llegando del dominio anterior al nuevo pero eventualmente Google va a empezar a desindexar el sitio y empezaras a perder tráfico y al inicio puede ser que no entiendas por qué.
Para verificar esto, basta con usar una herramienta de auditoria como website auditor, screaming frog, ahrefs, semrush, etc y ver cuantas paginas están con NOINDEX y de esta forma descartar cualquier error de este tipo.
Error 3: agregar la directiva NOINDEX a paginas no permitidas en robots.txt
Nunca pongas en “no permitido” (disallow) en el robots.txt, contenido que quieres desindexar pues al hacerlo evitas que el crawler se entere de que esta el NOINDEX y por lo tanto no lo va a desindexar.
Una manera de darse cuenta de esto es verificando con herramientas si la página en cuestión sigue recibiendo tráfico orgánico. Si una página desindexada sigue recibiendo tráfico orgánico significa que sigue indexada y en ese momento puedes verificar robots.txt.
Y bueno, esto es todo lo importante creo yo sobre el meta robots, espero que te sirva y si tienes dudas puedes dejarlas en los comentarios o el grupo de Facebook de SEO.




