Preguntas y respuestas de BERT
Una patente concedida a Google el 11 de mayo de 2021 implica la realización de tareas de procesamiento del lenguaje natural («PNL»), como la respuesta a preguntas. Se basa en un modelo de lenguaje que ha sido previamente entrenado utilizando el conocimiento del mundo.
La patente nos dice que los avances recientes en la formación previa de modelos de lenguaje han dado como resultado modelos de lenguaje como Representaciones de codificador bidireccional de Transformers («BERT»), que se ha discutido durante el último año cuando se trata de Google. La patente también nos dice que el uso de un transformador de transferencia de texto a texto («T5») puede capturar una gran cantidad de conocimiento mundial, basado en corpus de texto masivos en los que se ha entrenado ese modelo de lenguaje.
La patente señala un problema relacionado con el uso de un modelo de lenguaje que acumula cada vez más conocimiento. Señalaron que almacenar ese conocimiento implícitamente en los parámetros de una red neuronal puede hacer que la red aumente de tamaño significativamente. Esto podría afectar negativamente al funcionamiento del sistema.
La patente comienza con esa información y luego pasa a un resumen, que nos dice cómo podría funcionar el proceso descrito en la patente.
Nos dice que funciona con sistemas y métodos para el entrenamiento previo y el ajuste fino de modelos de lenguaje basados en redes neuronales.
Con más detalle, nos dice que la tecnología se relaciona con el aumento del preentrenamiento y el ajuste fino del modelo de lenguaje mediante el uso de un recuperador de conocimientos textuales basado en redes neuronales que se entrena junto con el modelo de lenguaje. Afirma:
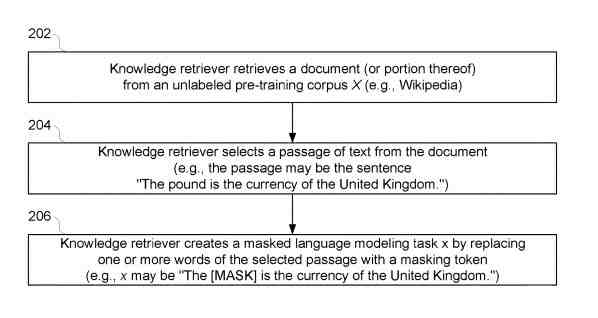
Durante el proceso de formación previa, el recuperador de conocimientos obtiene documentos (o partes de los mismos) de un corpus de formación previa sin etiquetar (por ejemplo, una o más enciclopedias en línea). El recuperador de conocimientos genera automáticamente un ejemplo de capacitación al muestrear un pasaje de texto de uno de los documentos recuperados y enmascarar aleatoriamente uno o más tokens en el fragmento de texto muestreado (p. Ej., «La [MÁSCARA] es la moneda del Reino Unido». ).
Señala esta característica de enmascaramiento específicamente:
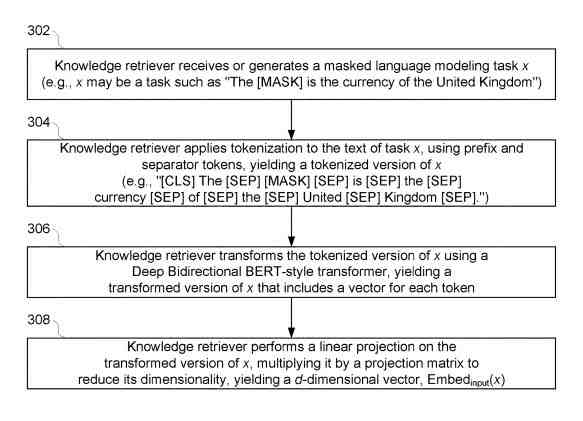
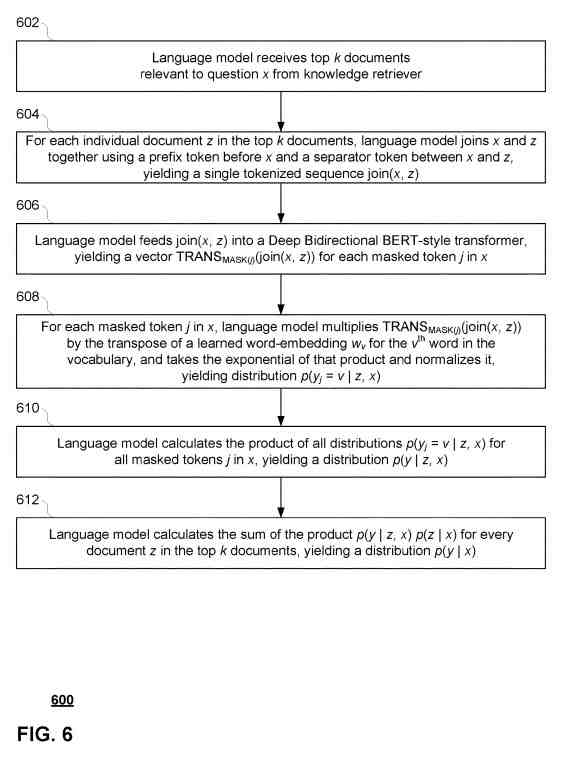
El recuperador de conocimientos también recupera documentos adicionales de un corpus de conocimientos para ser utilizados por el modelo de lenguaje al predecir la palabra que debe ir en cada token enmascarado. Luego, el modelo de lenguaje modela las probabilidades de cada documento recuperado para predecir los tokens enmascarados y usa esas probabilidades para clasificar y volver a clasificar continuamente los documentos (o algún subconjunto de los mismos) en términos de su relevancia.
Un modelo de lenguaje como BERT se puede utilizar para muchas funciones, y la patente también las señala, y nos habla específicamente sobre la respuesta a preguntas de BERT:
El recuperador de conocimientos y el modelo de lenguaje se ajustan a continuación mediante un conjunto de tareas diferentes. Por ejemplo, el recuperador de conocimientos puede ajustarse mediante tareas de preguntas y respuestas de dominio abierto («QA abierto»), en las que el modelo de lenguaje debe intentar predecir respuestas a un conjunto de preguntas directas (p. Ej., ¿Cuál es el capital de California?). Durante esta etapa de ajuste, el recuperador de conocimientos utiliza sus clasificaciones de relevancia aprendidas para recuperar documentos útiles para que el modelo de lenguaje responda a cada pregunta. El marco de la tecnología actual proporciona modelos que pueden recuperar de forma inteligente información útil de un gran corpus sin etiquetar, en lugar de requerir que toda la información potencialmente relevante se almacene implícitamente en los parámetros de la red neuronal. Por lo tanto, este marco puede reducir el espacio de almacenamiento y la complejidad de la red neuronal y también permitir que el modelo maneje de manera más efectiva nuevas tareas que pueden ser diferentes de aquellas en las que se entrenó previamente.
La patente describe el entrenamiento de un modelo de lenguaje mediante:
- Usando uno o más procesadores de un sistema de procesamiento, una tarea de modelado de lenguaje enmascarado usando texto de un primer documento
- Generar un vector de entrada aplicando una primera función de incrustación aprendida a la tarea de modelado de lenguaje enmascarado
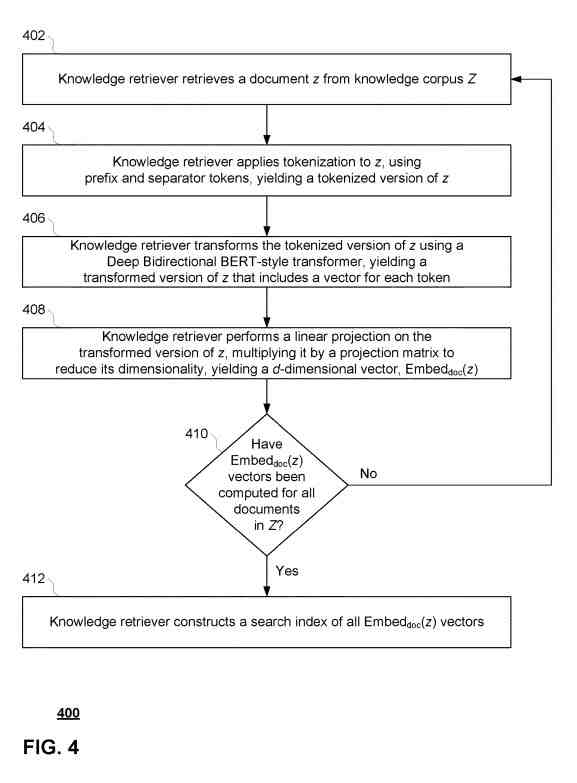
- Generar un vector de documento para cada documento de un corpus de conocimiento aplicando una segunda función de incrustación aprendida a cada documento del corpus de conocimiento, comprendiendo el corpus de conocimiento una primera pluralidad de documentos
- Generar una puntuación de relevancia para cada documento dado del corpus de conocimiento basado en el vector de entrada y el vector de documento para el documento dado
- Generar una primera distribución en base a la puntuación de relevancia de cada documento en el segundo número de documentos, siendo la segunda pluralidad de documentos del corpus de conocimiento
- Generar una segunda distribución basada en la tarea de modelado de lenguaje enmascarado y el texto de cada documento en la segunda pluralidad de documentos.
- Generando una tercera distribución basada en la primera distribución y la segunda distribución
- Modificar los parámetros de al menos la primera función de incrustación aprendida o la segunda función de incrustación aprendida para generar una primera distribución actualizada y una tercera distribución actualizada.
Cuando salió BERT, estaba destinado a ayudar con alrededor de 11 tareas de PNL, incluida la respuesta a preguntas. Proporcioné un vistazo al resumen de la patente y algunas de las imágenes que acompañan a ese resumen, pero el proceso final es mucho más detallado. Esta declaración de la patente me recordó una adquisición previa por parte de Google de Wavii (con Wavii, ¿Google adquirió el futuro de la búsqueda web?):
En algunos aspectos, uno o más procesadores del sistema se configuran además para recibir una tarea de consulta, comprendiendo la tarea de consulta una pregunta de dominio abierto y una tarea de respuesta; generar un vector de entrada de consulta aplicando la primera función de incrustación aprendida a la tarea de consulta, incluyendo la primera función de incrustación aprendida uno o más parámetros modificados como resultado de la modificación; generar una puntuación de relevancia de la consulta para cada documento dado del corpus de conocimiento basado en el vector de entrada de la consulta y el vector de documento para el documento dado; y recuperar la tercera pluralidad de documentos del corpus de conocimiento basándose en la puntuación de relevancia de la consulta de cada documento en la tercera pluralidad de documentos.
La patente se puede encontrar en:
Pre-entrenamiento y ajuste del modelo de lenguaje aumentado de recuperación
Inventores: Kenton Chiu Tsun Lee, Kelvin Gu, Zora Tung, Panupong Pasupat y Ming-Wei Chang
Cesionario: Google LLC
Patente de EE. UU.: 11,003,865
Concedido: 11 de mayo de 2021
Archivado: 20 de mayo de 2020
Resumen
Se describen sistemas y métodos para el entrenamiento previo y el ajuste fino de modelos de lenguaje basados en redes neuronales. Un recuperador de conocimientos textuales basado en redes neuronales se entrena junto con el modelo de lenguaje. En algunos ejemplos, el recuperador de conocimientos obtiene documentos de un corpus de formación previa sin etiquetar, genera sus propias tareas de formación y aprende a recuperar documentos relevantes para esas tareas. En algunos ejemplos, el recuperador de conocimientos se refina aún más mediante preguntas supervisadas de control de calidad abierto. El marco de la tecnología actual proporciona modelos que pueden recuperar de forma inteligente información útil de un gran corpus sin etiquetar, en lugar de requerir que toda la información potencialmente relevante se almacene implícitamente en los parámetros de la red neuronal. Por lo tanto, este marco puede reducir el espacio de almacenamiento y la complejidad de la red neuronal y también permitir que el modelo maneje de manera más efectiva nuevas tareas que pueden ser diferentes de aquellas en las que se entrenó previamente.
Más recursos sobre BERT y sobre la respuesta a preguntas de BERT
Hay un artículo sobre BERT que vale la pena leer para ver cómo se usa: BERT: Pre-entrenamiento de transformadores bidireccionales profundos para la comprensión del lenguaje
Uno de los autores del artículo BERT también fue uno de los inventores de esta patente, y parece que también hay una lectura interesante en su página de inicio: Página de inicio de Ming-Wei Chang
También puede valer la pena visitar esta patente porque, si bien he presentado un resumen de cómo Google puede usar la respuesta a preguntas BERT, la patente proporciona una visión mucho más detallada de cómo el motor de búsqueda puede usar la tecnología detrás de ella.
Algunos aspectos de eso incluyen:
Según los aspectos de la tecnología, un modelo de lenguaje basado en redes neuronales residente en el sistema de procesamiento se entrena previamente utilizando tareas de modelado de lenguaje enmascarado. Cada tarea de modelado de lenguaje enmascarado puede ser generada automáticamente por un recuperador de conocimientos basado en redes neuronales (también residente en el sistema de procesamiento), lo que permite que el entrenamiento previo se lleve a cabo sin supervisión.
Por ejemplo, el corpus de entrenamiento previo puede ser una enciclopedia en línea como Wikipedia, y el documento recuperado puede ser una página HTML completa para una entrada determinada, una sección seleccionada o secciones de la página (por ejemplo, título, cuerpo, tablas). , un solo párrafo u oración, etc. En el paso 204, el recuperador de conocimientos selecciona un pasaje de texto del documento para enmascararlo. Por ejemplo, el recuperador de conocimientos puede seleccionar una sola oración del documento, como «La libra es la moneda del Reino Unido». Finalmente, en el paso 206, el recuperador de conocimientos crea una tarea x de modelado de lenguaje enmascarado reemplazando una o más palabras del pasaje seleccionado con una ficha de enmascaramiento (por ejemplo, «[MÁSCARA]» o cualquier otra ficha adecuada). Por ejemplo, continuando con el mismo ejemplo del paso 204, el recuperador de conocimientos puede enmascarar «libra» dentro del pasaje seleccionado, de modo que la tarea de modelado de lenguaje enmascarado x se convierta en «La [MÁSCARA] es la moneda del Reino Unido».
Por ejemplo, el corpus de conocimiento Z puede ser un corpus sin etiquetar como Wikipedia o algún otro sitio web. En ese sentido, el corpus de conocimiento Z puede ser el mismo que el corpus X previo al entrenamiento, puede tener solo algo de superposición con el corpus X previo al entrenamiento, o tal vez completamente diferente del corpus X previo al entrenamiento. En implementaciones donde el corpus Z de conocimiento es el mismo como corpus X previo al entrenamiento, el documento particular seleccionado para generar la tarea x de modelado de lenguaje enmascarado puede ser eliminado del corpus Z de conocimiento antes de que comience el entrenamiento previo. Evite entrenar el modelo del lenguaje, acostumbrándose demasiado a encontrar respuestas a través de coincidencias de cadenas exactas.
Esto es solo un breve vistazo a cómo funciona la respuesta a preguntas BERT y lo que ofrece la patente. Se recomienda que lea el resto de la patente y lea el documento para obtener más información sobre cómo se puede utilizar la respuesta a preguntas BERT para entrenar previamente un corpus grande a fin de proporcionar respuestas para la respuesta a preguntas.





