Google ha anunciado el lanzamiento de una tecnología mejorada que facilita y acelera la investigación y el desarrollo de nuevos algoritmos que se pueden implementar rápidamente.
Esto le da a Google la capacidad de crear rápidamente nuevos algoritmos anti-spam, mejorar el procesamiento del lenguaje natural y los algoritmos relacionados con la clasificación y poder ponerlos en producción más rápido que nunca.
La clasificación TF mejorada coincide con las fechas de las actualizaciones recientes de Google
Esto es de interés porque Google ha implementado varios algoritmos de lucha contra el spam y dos actualizaciones de algoritmos centrales en junio y julio de 2021. Esos desarrollos siguieron directamente a la publicación de mayo de 2021 de esta nueva tecnología.
El momento podría ser una coincidencia, pero teniendo en cuenta todo lo que hace la nueva versión de TF-Ranking basado en Keras, puede ser importante familiarizarse con él para comprender por qué Google ha aumentado el ritmo de lanzamiento de nuevas actualizaciones de algoritmos relacionados con el ranking.
Nueva versión de TF-Ranking basado en Keras
Google anunció una nueva versión de TF-Ranking que se puede utilizar para mejorar el aprendizaje neuronal para clasificar los algoritmos, así como los algoritmos de procesamiento del lenguaje natural como BERT.
Es una forma poderosa de crear nuevos algoritmos y amplificar los existentes, por así decirlo, y hacerlo de una manera increíblemente rápida.
Clasificación de TensorFlow
Según Google, TensorFlow es una plataforma de aprendizaje automático.
En un video de YouTube de 2019, la primera versión de TensorFlow Ranking se describió como:
«La primera biblioteca de aprendizaje profundo de código abierto para aprender a clasificar (LTR) a escala».
La innovación de la plataforma TF-Ranking original fue que cambió la forma en que se clasificaban los documentos relevantes.
Los documentos anteriormente relevantes se compararon entre sí en lo que se denomina clasificación por pares. La probabilidad de que un documento sea relevante para una consulta se comparó con la probabilidad de otro elemento.
Esta fue una comparación entre pares de documentos y no una comparación de la lista completa.
La innovación de TF-Ranking es que permitió la comparación de toda la lista de documentos a la vez, lo que se denomina puntuación de varios elementos. Este enfoque permite mejores decisiones de clasificación.
La clasificación TF mejorada permite un rápido desarrollo de nuevos y potentes algoritmos
El artículo de Google publicado en su Blog de IA dice que el nuevo TF-Ranking es un lanzamiento importante que hace que sea más fácil que nunca configurar modelos de aprendizaje para clasificar (LTR) y ponerlos en producción en vivo más rápido.
Esto significa que Google puede crear nuevos algoritmos y agregarlos para buscar más rápido que nunca.
El artículo dice:
“Nuestro modelo de clasificación nativo de Keras tiene un diseño de flujo de trabajo completamente nuevo, que incluye un ModelBuilder flexible, un DatasetBuilder para configurar los datos de entrenamiento y un Pipeline para entrenar el modelo con el conjunto de datos proporcionado.
Estos componentes hacen que la construcción de un modelo LTR personalizado sea más fácil que nunca y facilitan la exploración rápida de nuevas estructuras de modelos para la producción y la investigación «.
TF-Ranking BERT
Cuando un artículo o trabajo de investigación afirma que los resultados fueron ligeramente mejores, ofrece salvedades y afirma que se necesitaba más investigación, eso es una indicación de que el algoritmo en discusión podría no estar en uso porque no está listo o es un callejón sin salida.
Ese no es el caso de TFR-BERT , una combinación de TF-Ranking y BERT.
BERT es un enfoque de aprendizaje automático para el procesamiento del lenguaje natural. Es una forma de comprender las consultas de búsqueda y el contenido de la página web.
BERT es una de las actualizaciones más importantes de Google y Bing en los últimos años.
El artículo establece que la combinación de TF-R con BERT para optimizar el orden de las entradas de la lista generó » mejoras significativas «.
Esta afirmación de que los resultados fueron significativos es importante porque aumenta la probabilidad de que algo como esto esté actualmente en uso.
La implicación es que TF-Ranking basado en Keras hizo que BERT fuera más poderoso.
Según Google:
«Nuestra experiencia muestra que esta arquitectura TFR-BERT ofrece mejoras significativas en el rendimiento del modelo de lenguaje previamente entrenado, lo que lleva a un rendimiento de vanguardia para varias tareas de clasificación populares …»
TF-Ranking y GAM
Hay otro tipo de algoritmo, llamado Modelos Aditivos Generalizados (GAM), que TF-Ranking también mejora y hace una versión aún más poderosa que la original.
Una de las cosas que hace que este algoritmo sea importante es que es transparente en el sentido de que todo lo que implica generar el ranking se puede ver y comprender.
Google explicó la importancia de la transparencia de esta manera:
“La transparencia y la interpretabilidad son factores importantes en la implementación de modelos LTR en sistemas de clasificación que pueden estar involucrados en la determinación de los resultados de procesos como la evaluación de elegibilidad de préstamos, la orientación de anuncios o la orientación de decisiones de tratamiento médico.
En tales casos, la contribución de cada característica individual a la clasificación final debe ser examinada y comprensible para garantizar la transparencia, la responsabilidad y la equidad de los resultados «.
El problema con los GAM es que no se sabía cómo aplicar esta tecnología a los problemas de tipo de clasificación.
Para resolver este problema y poder usar GAM en una configuración de clasificación, se utilizó TF-Ranking para crear modelos aditivos generalizados (GAM) de clasificación neuronal que están más abiertos a cómo se clasifican las páginas web.
Google lo llama Aprendizaje de clasificación interpretable .
Esto es lo que dice el artículo de Google AI:
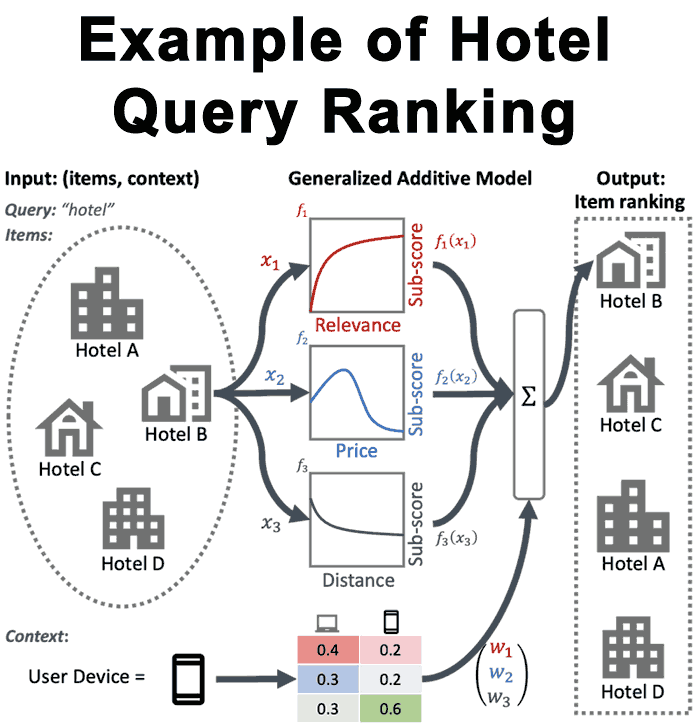
“Con este fin, hemos desarrollado un GAM de clasificación neuronal, una extensión de los modelos aditivos generalizados a los problemas de clasificación.
A diferencia de los GAM estándar, un GAM de clasificación neuronal puede tener en cuenta tanto las características de los elementos clasificados como las características del contexto (p. Ej., Consulta o perfil de usuario) para derivar un modelo compacto e interpretable.
Por ejemplo, en la figura siguiente, el uso de una clasificación neuronal GAM permite ver cómo la distancia, el precio y la relevancia, en el contexto de un dispositivo de usuario determinado, contribuyen a la clasificación final del hotel.
Los GAM de clasificación neuronal ahora están disponibles como parte de TF-Ranking … «
 Le pregunté a Jeff Coyle , cofundador de la tecnología de optimización de contenido de IA MarketMuse ( @MarketMuseCo ), sobre TF-Ranking y GAM.
Le pregunté a Jeff Coyle , cofundador de la tecnología de optimización de contenido de IA MarketMuse ( @MarketMuseCo ), sobre TF-Ranking y GAM.
Jeffrey, que tiene experiencia en informática y décadas de experiencia en marketing de búsqueda, señaló que las GAM son una tecnología importante y mejorarla fue un evento importante.
Coyle compartió:
“He dedicado mucho tiempo a investigar la innovación de GAM de clasificación neuronal y el posible impacto en el análisis de contexto (para consultas), que ha sido un objetivo a largo plazo de los equipos de puntuación de Google.
Neural RankGAM y las tecnologías relacionadas son armas mortales para la personalización (en particular, los datos del usuario y la información del contexto, como la ubicación) y para el análisis de intenciones.
Con keras_dnn_tfrecord.py disponible como ejemplo público, podemos vislumbrar la innovación en un nivel básico.
Recomiendo que todos consulten ese código «.
Árboles de decisión mejorados con gradiente superior al rendimiento (BTDT)
Superar el estándar en un algoritmo es importante porque significa que el nuevo enfoque es un logro que mejora la calidad de los resultados de búsqueda.
En este caso, el estándar son los árboles de decisión impulsados por gradientes (GBDT), una técnica de aprendizaje automático que tiene varias ventajas.
Pero Google también explica que los GBDT también tienen desventajas:
“Los GBDT no se pueden aplicar directamente a grandes espacios de características discretas, como el texto del documento sin formato. También son, en general, menos escalables que los modelos de clasificación neuronal «.
En un artículo de investigación titulado, ¿Siguen superando a los rankers neuronales los árboles de decisión potenciados por gradientes? los investigadores afirman que el aprendizaje neuronal para clasificar los modelos es » por un amplio margen inferior» a … las implementaciones basadas en árboles. »
Los investigadores de Google utilizaron el nuevo TF-Ranking basado en Keras para producir lo que llamaron, modelo de cruz latente auto-atenta aumentada de datos (DASALC).
DASALC es importante porque puede igualar o superar las líneas de base actuales del estado de la técnica:
“Nuestros modelos pueden funcionar comparativamente con la sólida línea de base basada en árboles, mientras superan el aprendizaje neuronal publicado recientemente para clasificar los métodos por un amplio margen. Nuestros resultados también sirven como punto de referencia para el aprendizaje neuronal para clasificar modelos «.
TF-Ranking basado en Keras acelera el desarrollo de algoritmos de ranking
La conclusión importante es que este nuevo sistema acelera la investigación y el desarrollo de nuevos sistemas de clasificación, que incluyen la identificación de spam para clasificarlos fuera de los resultados de búsqueda.
El artículo concluye:
“Considerándolo todo, creemos que la nueva versión TF-Ranking basada en Keras facilitará la realización de investigaciones neuronales de LTR y la implementación de sistemas de clasificación de grado de producción”.
Google ha estado innovando a un ritmo cada vez más rápido en los últimos meses, con varias actualizaciones de algoritmos de spam y dos actualizaciones de algoritmos centrales en el transcurso de dos meses.
Estas nuevas tecnologías pueden ser la razón por la que Google ha estado implementando tantos algoritmos nuevos para mejorar la lucha contra el spam y la clasificación de los sitios web en general.
Citas
Artículo del blog de IA de Google
Nuevo algoritmo DASALC de Google
¿Siguen superando a los rankers neuronales los árboles de decisión potenciados por gradientes?
Sitio web oficial de TensorFlow
Página de GitHub de TensorFlow Ranking v0.4.0
https://github.com/tensorflow/ranking/releases/tag/v0.4.0
Ejemplo de Keras keras_dnn_tfrecord.py





