Un equipo de científicos de Google Research, el Instituto Alan Turing y la Universidad de Cambridge presentó recientemente un nuevo transformador multimodal de última generación (SOTA) para IA.
En otras palabras, le están enseñando a la IA cómo ‘oír’ y ‘ver’ al mismo tiempo.
Al frente: probablemente hayas oído hablar de los sistemas de IA de transformadores como GPT-3. En esencia, procesan y categorizan datos de un tipo específico de flujo de medios.
Bajo el paradigma actual de SOTA, si quisiera analizar los datos de un video, necesitaría varios modelos de IA ejecutándose al mismo tiempo.
Necesitaría un modelo que haya sido entrenado en videos y otro modelo que haya sido entrenado en clips de audio. Esto se debe a que, al igual que sus ojos y oídos humanos son sistemas completamente diferentes (pero conectados), los algoritmos necesarios para procesar diferentes tipos de audio suelen ser diferentes a los que se usan para procesar video.
Según el artículo del equipo:
A pesar de los avances recientes en diferentes dominios y tareas, los métodos de vanguardia actuales entrenan un modelo separado con diferentes parámetros de modelo para cada tarea en cuestión. En este trabajo, presentamos un método simple pero efectivo de entrenar un modelo único y unificado que logra resultados competitivos o de vanguardia para la clasificación de imágenes, videos y audio.
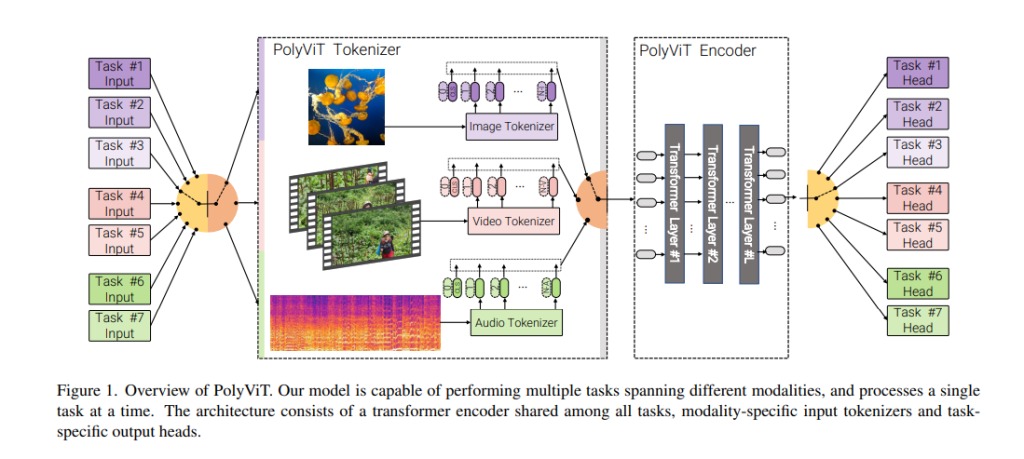
Antecedentes: Lo increíble aquí es que el equipo no solo pudo construir un sistema multimodal capaz de manejar sus tareas relacionadas simultáneamente, sino que al hacerlo lograron superar a los modelos SOTA actuales que se enfocan en una sola tarea.
Los investigadores llaman a su sistema «PolyVit». Y, según ellos, actualmente prácticamente no tiene competencia:
Al co-entrenar diferentes tareas en una sola modalidad, podemos mejorar la precisión de cada tarea individual y lograr resultados de vanguardia en 5 conjuntos de datos de clasificación de audio y video estándar. El entrenamiento conjunto de PolyViT en múltiples modalidades y tareas conduce a un modelo que es aún más eficiente en cuanto a parámetros y aprende representaciones que se generalizan en múltiples dominios.
Además, mostramos que el co-entrenamiento es simple y práctico de implementar, ya que no necesitamos ajustar los hiperparámetros para cada combinación de conjuntos de datos, sino que simplemente podemos adaptar los del entrenamiento estándar de una sola tarea.
Toma rápida: esto podría ser un gran problema para el mundo empresarial. Uno de los mayores problemas que enfrentan las empresas que esperan implementar pilas de IA es la compatibilidad. Hay literalmente cientos de soluciones de aprendizaje automático y no hay garantías de que funcionen juntas.
Esto da como resultado implementaciones monopolísticas en las que los líderes de TI se quedan con un solo proveedor por motivos de compatibilidad o un enfoque de combinación y combinación que conlleva más dolores de cabeza de los que normalmente vale la pena.
Un paradigma en el que los sistemas multimodales se conviertan en la norma sería una bendición para los administradores cansados.
Por supuesto, esta es una investigación preliminar de un documento preimpreso, por lo que no hay razón para creer que veremos esto implementado ampliamente en el corto plazo.
Pero es un gran paso hacia un sistema de clasificación único para todos, y eso es algo bastante emocionante.
Mas informacion: Synced