Hola, Harold de nuevo por aquí, en esta décima entrega del curso/guía para aprender a usar Screaming Frog como un profesional.
Generalmente, hay cierta tolerancia por contenido duplicado dentro de las webs de parte del algoritmo de Google, y es un tema que Google ha aclarado en varias ocasiones: el contenido duplicado no es un factor de posicionamiento negativo. Aun así, hay cierto contenido que debería ser único por cada URL, el contenido esencial y es sobre lo que nos vamos a centrar esta vez.
Lo primero que debes tener claro es que contenido es irrelevante que este duplicado en tu web y cual no debería. Si intentas posicionar la palabra clave “¿Qué es una alergia” para la URL “/alergia-definicion/”, tener el mismo contenido (parte de él) de que es una alergia en la URL “/remedios-alergias/” si podría ser perjudicial ya que, aunque sea poco texto, el algoritmo posicionaría una de las dos URLs para la keyword “¿Qué es una alergia?” y podría elegir la equivocada para ti.
En cambio, tener un texto en todas las URLs como por ejemplo “Distribuidor autorizado de Samsung” no es un texto que te va a perjudicar en lo absoluto. ¿Ves la diferencia?
Corregir este tipo de detalles te evita canibalizaciones y por ende te puede ayudar a mejorar el posicionamiento de tu web. Esta es una revisión que realizo periódicamente después de agregar nuevo contenido durante un tiempo.
¿Qué vas a aprender hoy?
- Que contenido duplicado es perjudicial y cual es irrelevante
- Encontrar contenido casi duplicado en una web
- Encontrar contenido duplicado en una web
- Aprender a decidir que contenido duplicado merece tu atención y cual no.
Vamos a ello, pero antes
Configuración de Screaming Frog
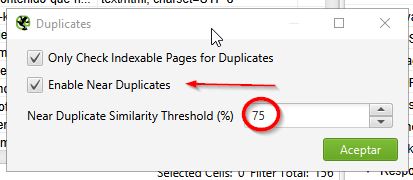
1) Habilitar la opción “Near Duplicates”, para esto ve a “Configuration > Content > Duplicates“ y marca la casilla “Near duplicates”.
2) Marca el umbral en un 75% (Near Duplicate Similarity Threshold (%)), este valor sirve para indicarle a Screaming Frog que tan parecido tiene que ser un texto para ser considerado como igual a otro, mientras más alto, significa que tiene que ser más parecido, menos alto, hay menos parecido. Yo siempre lo pruebo en 75% y después veo si debo cambiarlo o no.
3) Configurar el área de contenido (Content Area): en esta configuración le indicas a Screaming Frog donde se encuentra el contenido de tu web y separas todo aquello que no es parte de él, por ejemplo header, menú de navegacion, footer, sidebar, etc.
Para esto, ve a “Configuration > Content > Area” y veras esta pantalla:
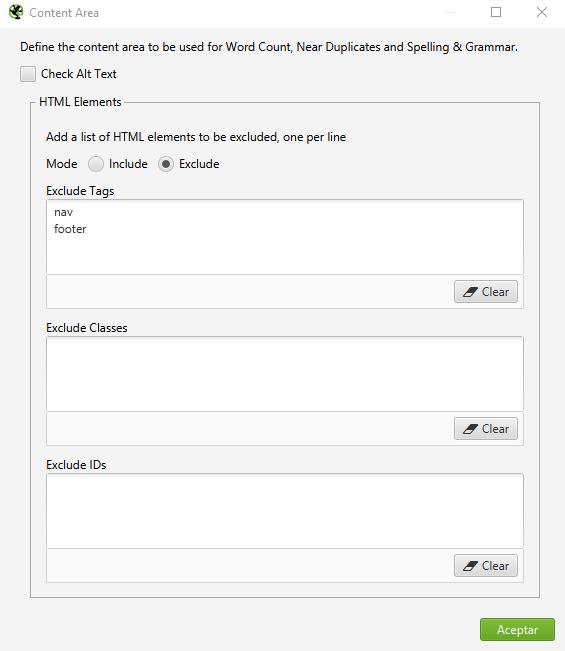
Check Alt Text: si lo marcas le dirás al crawler que el ALT TEXT de las imágenes es parte del contenido, yo no lo marco.
Tags/Classes/IDs: Existen 3 formas de indicarle los grupos de contenido a Screaming Frog, Tags que hace referencia a los HTML Tags, por ejemplo nav, article, div, etc.
Classes hace referencia a una clase de CSS que pueda tener el contenedor o tag, ejemplo <div class=”main-content”>CONTENIDO</div>
IDs hace referencia a un ID que se le puede colocar a los HTML tags, por ejemplo <div id=”main-content”>CONTENIDO</div>
Mode: Le indicas si la configuración que estas agregando debe ser incluida o excluida, es decir, si esos tags/classes/IDs deben ser tomados en cuenta o excluidos. Ejemplos:
- Imagina que el contenido está dentro del tag “article”, entonces en Mode eliges “Include” y en “Include Tags” colocas article.
- Si el contenido está dentro de un div que tiene una clase CSS llamada “main-content” entonces haces lo mismo que el punto anterior, pero colocas la clase en la sección “Include clases”
- c) Si el contenido está dentro del div id “main-content” entonces colocas main-content en “Include IDs”.
Para el caso de “Exclude” funciona similar, con la diferencia que los valores que agregues no serán considerados. Esto es muy útil cuando no hay un contenedor específico para el contenido pero si están claros el header, footer, sidebar.
¿Cómo obtienes el contenedor ya sea TAG, CLASS o ID?
Para obtener este o estos valores debes inspeccionar el código fuente de tu web con F12 o clic derecho inspeccionar. Siempre habrá varias opciones posibles por lo que debes testear o probar bien.
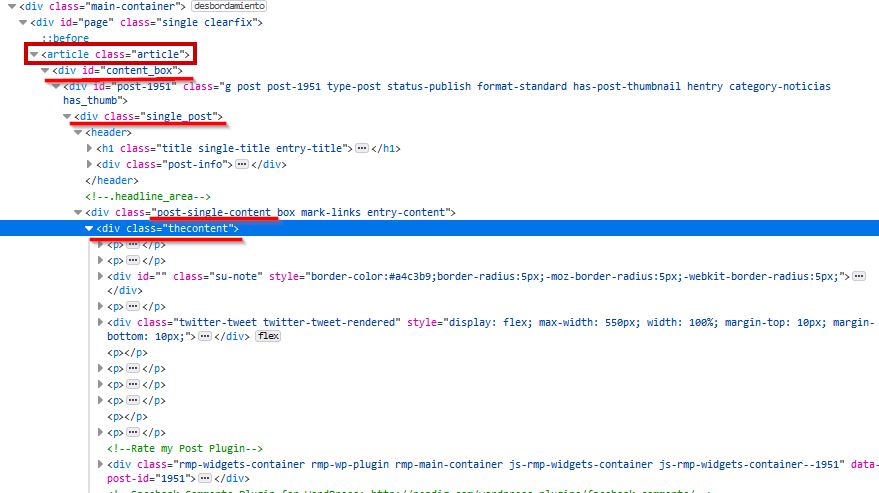
En el caso de hablemosdeseo.net (mira la imagen) todas las opciones marcadas se podrían usar, pero yo elegí la clase “thecontent” ya que a mi criterio es el mejor contenedor que envuelve al contenido.
Rastrear la web
Ahora debes rastrear la web, como tantas veces lo has hecho y vas a esperar a que termine…

Donde ver el contenido duplicado
Primero que nada, definir 2 cosas un poco diferentes, uno es el contenido duplicado y otro es el contenido “casi duplicado”, el primero es texto duplicado per se, pero el “casi duplicado” es aquel que se parece a otro.
El primero lo podrás ver inmediatamente después de terminar el rastreo (y aun durante el rastreo).
Para el segundo debes ir al menú principal y ejecutar el “Crawl Analysis”
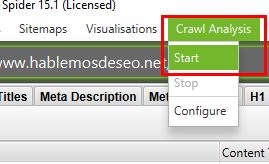
Ahh y debes asegurarte que en la configuración del Crawl Analysis está marcada la opción “Content” de lo contrario no lo analizara:
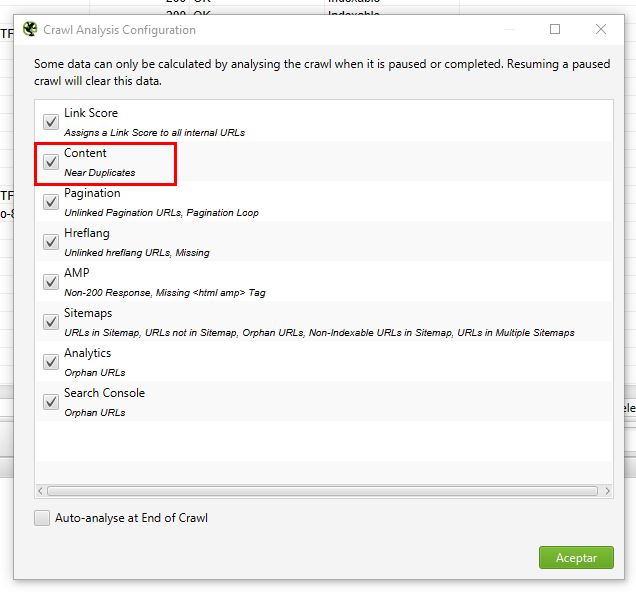
Cuando termine el crawl analysis, puedes ir al tab “Content” y con los filtros Exact Duplicates y Near Duplicates podrás ver si tienes este problema en tu web.
En hablemosdeseo.net no tengo este problema, así que para ejemplificar voy a crear dos entradas copias de otras con ligeros cambios únicamente para que veas el resultado.
Vuelvo a rastrear la web y un minuto más tarde… así es como veras el resultado si se encuentra contenido duplicado o casi duplicado.

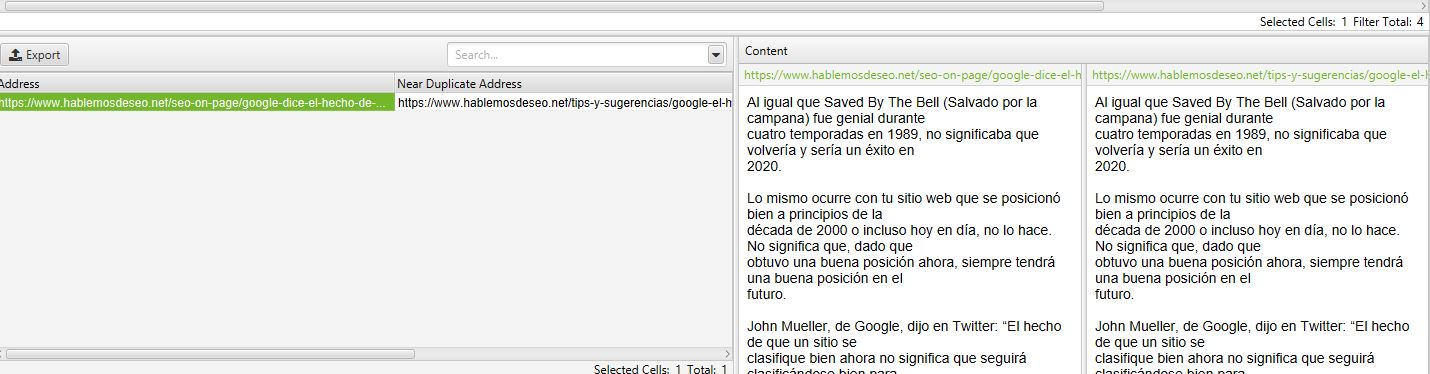
Si seleccionas una de las URLs marcadas como contenido duplicado y te vas a los paneles inferiores a “Duplicate details” podrás ver más detalles y los textos puestos a la par para que puedas ver mejor.
Si hay muchos resultados, también puedes exportar un listado en “Bulk Export > Content > Exact Duplicates” o “Near Duplicates”.
Un paso mas para encontrar contenido casi duplicado
Si quieres analizar el contenido cambiando el umbral de similitud o si el área (Content Area) que has elegido como contenido no te satisface, no tienes que realizar todo el rastreo nuevamente.
Únicamente cambia los ajustes necesarios ya sea en “Configuration > Content > Duplicates”, digamos, pasar el threshold de 75% a 60% (o el que desees) y puedes cambiar el Content Area.
Después de hacer los cambios, únicamente ejecuta nuevamente el crawl analysis y Screaming Frog va a reanalizar con la nueva configuración y listo.
¿Qué hacer con el contenido duplicado o casi duplicado?
Esta es una pregunta muy amplia, ya que como dije al inicio, hay ciertos casos en que tener partes de contenido en toda la web no es problema, así que mi consejo es que analices cada caso de forma individual y decidas que hacer, ya sea fusionar contenido, eliminar o editar.
Dependerá de tu sitio y tus objetivos.
Que has aprendido hoy
Esto ha sido todo, no es algo complicado, pero es un análisis muy valioso que te puede ayudar a encontrar canibalizaciones y corregir problemas para mejorar tu posicionamiento.
Si te ha gustado o te ha sido útil esta información, te invito a compartirla. Si tienes alguna duda o pregunta, déjala en los comentarios, con gusto la responderé.
Hasta la próxima.





